数据结构复习整理
Thanks: Codex & 连熬了两个通宵的我
根据
数据结构-复习提纲-2025级.ppt和第 1 到第 10 章课件整理。根据以往的经验来看,提纲中标红的(本文标题中加粗的)是会考大题的。
考试题型
题型与分值:
| 题型 | 分值 |
|---|---|
| 选择题 | 21% |
| 填空题 | 18% |
| 判断题 | 15% |
| 综合题 | 26% |
| 算法题 | 20% |
复习提纲问题逐一回答
1. 什么是栈?怎样判断非法出栈序列?如何共享两个栈?如何用两个栈完成单栈不便完成的操作?
栈是只允许在同一端进行插入和删除的线性表,插入端和删除端称为栈顶,另一端称为栈底。栈的特点是后进先出,LIFO。
判断出栈序列是否合法,通常采用模拟法:按给定入栈序列依次入栈,每次入栈后,只要栈顶元素等于当前希望出栈的元素,就立即出栈并匹配下一个目标元素。若最后目标出栈序列全部匹配,则合法;否则非法。
两个栈共享一个数组时,让栈 1 从数组左端向右增长,栈 2 从数组右端向左增长。初始 top1 = -1,top2 = MaxSize,栈满条件为 top1 + 1 == top2。这样可以动态共享中间空闲空间。
两个栈组合使用时,可以通过一个栈暂存、另一个栈输出,实现顺序反转、括号匹配、中缀转后缀、队列模拟等操作。例如用两个栈模拟队列:入队进栈 S1,出队时若 S2 为空,就把 S1 中元素依次弹出压入 S2,再从 S2 弹出。
2. 什么是线性表?它最主要的性质是什么?
线性表是由 n 个相同类型数据元素组成的有限序列,记为 L = (a1, a2, ..., an)。
它最主要的性质是线性关系:除第一个元素外,每个元素有且仅有一个直接前驱;除最后一个元素外,每个元素有且仅有一个直接后继。元素之间是一对一关系。
3. 什么是逻辑结构、数据元素、数据项、数据类型?它们有什么联系?
逻辑结构是数据元素之间的逻辑关系,与存储位置无关。数据元素是数据的基本单位,也可称为记录、结点、顶点。数据项是描述数据元素的最小单位,如学生记录中的学号、姓名。数据类型是一个值的集合以及定义在该集合上的一组操作。
联系是:数据项组成数据元素,数据元素按照某种逻辑关系形成数据结构;数据类型可看作已经在程序语言中实现的数据结构及其操作。
4. 什么是顺序存储结构?什么是链式存储结构?还有哪些存储结构?
顺序存储结构用一组地址连续的存储单元依次存放数据元素,逻辑相邻的元素物理位置也相邻,优点是支持随机存取,缺点是插入删除常需移动元素。
链式存储结构用结点存放数据元素,并用指针表示元素间逻辑关系。优点是插入删除方便,缺点是不能随机存取且指针占用额外空间。
其他常见存储结构包括索引存储和散列存储。索引存储用索引表加快查找;散列存储通过散列函数由关键字直接计算存储地址。
5. 什么是单链表、双向链表、循环链表?怎样插入和删除?
单链表的每个结点只有一个 next 指针,指向后继结点。双向链表的结点有 prior 和 next 两个指针,可同时访问前驱和后继。循环链表的尾结点指针指向头结点或首元结点,形成环。
单链表在结点 p 后插入 s:
s->next = p->next;
p->next = s;删除 p 后继结点:
q = p->next;
p->next = q->next;
free(q);双向链表在 p 后插入 s:
s->next = p->next;
s->prior = p;
p->next->prior = s;
p->next = s;删除双向链表中的结点 p:
p->prior->next = p->next;
p->next->prior = p->prior;
free(p);6. 什么是 AVL 树?什么是二叉搜索树?如何插入和删除?
二叉搜索树 BST 是满足以下性质的二叉树:左子树所有关键字小于根结点关键字,右子树所有关键字大于根结点关键字,左右子树也分别是二叉搜索树。插入时从根开始比较,找到空位置插入为叶子。删除分三种情况:叶子直接删;只有一个孩子则用孩子替代;有两个孩子则用中序前驱或中序后继替代,再删除该前驱或后继。
AVL 树是平衡二叉搜索树,任一结点左右子树高度差的绝对值不超过 1。AVL 插入或删除后若失衡,需要旋转调整:LL 型右旋,RR 型左旋,LR 型先左旋再右旋,RL 型先右旋再左旋。
7. 有向图存在拓扑序列的充分必要条件是什么?按拓扑序重编号后邻接矩阵怎样变化?
有向图存在拓扑序列的充分必要条件是该图为有向无环图,即 DAG。因为拓扑序列要求,有向边的前者出现在后者之前,故不能出现环。
拓扑排序过程是:反复选择入度为 0 的顶点输出,删除该顶点及其所有出边。若所有顶点都能输出,则存在拓扑序列;若中途不存在入度为 0 的顶点但仍有顶点未输出,则图中存在环。
若得到一个拓扑序列后,把各顶点编号改为它们在拓扑序列中的下标,则每条有向边都从编号小的顶点指向编号大的顶点。因此邻接矩阵中非零元素只会出现在主对角线以上,即邻接矩阵呈上三角形式。
8. 有哪些经典排序算法?查找第 k 大或第 k 小是否必须完全排序?如何高效获取?
经典排序算法包括直接插入排序、折半插入排序、希尔排序、冒泡排序、快速排序、简单选择排序、堆排序、二路归并排序、基数排序。
查找第 k 大或第 k 小不一定要完全排序。可以使用快速选择算法,也就是快速排序中的划分思想。一次划分后枢轴元素到达最终位置,若枢轴位置正好是第 k 个,则直接返回;若目标在左侧,只递归左侧;若目标在右侧,只递归右侧。平均时间复杂度为 O(n),最坏为 O(n^2)。
使用快速选择算法,代码如下:
int partition(int A[], int low, int high) {
int pivot = A[low];
while (low < high) {
// 从右开始寻找比枢轴小的元素,放到左边
while (low < high && A[high] >= pivot) high--;
A[low] = A[high];
// 从左开始寻找比枢轴大的元素,放到右边
while (low < high && A[low] <= pivot) low++;
A[high] = A[low];
}
// 左右均已固定,枢轴位置固定
A[low] = pivot;
return low;
}
int quickSelect(int A[], int n, int k) {
int low = 0;
int high = n - 1;
int target = k - 1;
while (low <= high) {
int pos = partition(A, low, high);
if (pos == target) {
return A[pos];
} else if (pos > target) {
high = pos - 1;
} else {
low = pos + 1;
}
}
return -1;
}也可以使用堆。求第 k 小可维护一个大小为 k 的大根堆;求第 k 大可维护一个大小为 k 的小根堆。复杂度通常为 O(n log k)。
使用堆,代码如下:
using namespace std;
// ---------- 大根堆:用于求第 k 小 ----------
// 建堆过程:
// 从最后一个非叶子结点开始,每个结点和较大的孩子比较
// 如果孩子更大,就把孩子上移、当前元素下沉
// 调整到都满足
void adjustDownMax(vector<int>& heap, int n, int i) {
int temp = heap[i];
for (int child = 2 * i + 1; child < n; child = 2 * child + 1) {
// 如果右孩子比左孩子大,则选择目标为右孩子
if (child + 1 < n && heap[child + 1] > heap[child]) {
child++;
}
// 如果孩子比当前结点小,跳过
if (heap[child] <= temp) {
break;
}
// (孩子比当前结点大,)孩子上移
heap[i] = heap[child];
i = child;
}
// 当前元素下沉
heap[i] = temp;
}
void buildMaxHeap(vector<int>& heap, int n) {
// 从 floor((n - 2) / 2) 开始调整
for (int i = (n - 2) / 2; i >= 0; i--) {
adjustDownMax(heap, n, i);
}
}
int kthSmallest(vector<int> a, int k) {
int n = a.size();
vector<int> heap;
for (int i = 0; i < k; i++) {
heap.push_back(a[i]);
}
buildMaxHeap(heap, k);
for (int i = k; i < n; i++) {
if (a[i] < heap[0]) {
heap[0] = a[i];
adjustDownMax(heap, k, 0);
}
}
return heap[0];
}
// ---------- 小根堆:用于求第 k 大 ----------
void adjustDownMin(vector<int>& heap, int n, int i) {
int temp = heap[i];
for (int child = 2 * i + 1; child < n; child = 2 * child + 1) {
if (child + 1 < n && heap[child + 1] < heap[child]) {
child++;
}
if (heap[child] >= temp) {
break;
}
heap[i] = heap[child];
i = child;
}
heap[i] = temp;
}
void buildMinHeap(vector<int>& heap, int n) {
for (int i = (n - 2) / 2; i >= 0; i--) {
adjustDownMin(heap, n, i);
}
}
int kthLargest(vector<int> a, int k) {
int n = a.size();
vector<int> heap;
for (int i = 0; i < k; i++) {
heap.push_back(a[i]);
}
buildMinHeap(heap, k);
for (int i = k; i < n; i++) {
if (a[i] > heap[0]) {
heap[0] = a[i];
adjustDownMin(heap, k, 0);
}
}
return heap[0];
}若是使用 priority_queue 则可以简化很多:
// 求第 k 小:维护大小为 k 的大根堆
// 思路:
// 堆里面始终保留当前见过的 k 个最小的元素
// 如果堆大小超过 k,就把最大的弹出
// 最后的堆顶就是这 k 个里面最大的,也就是第 k 小
int kthSmallest(vector<int>& a, int k) {
priority_queue<int> heap; // 大根堆
for (int x : a) {
heap.push(x);
if (heap.size() > k) {
heap.pop(); // 弹出当前最大的
}
}
return heap.top(); // 剩下 k 个较小元素中最大的即为第 k 小
}
// 求第 k 大:维护大小为 k 的小根堆
// 思路:
// 堆里面始终保留当前见过的 k 个最大的元素
// 如果堆大小超过 k,就把最小的弹出
// 最后的堆顶就是这 k 个里面最小的,也就是第 k 大
int kthLargest(vector<int>& a, int k) {
priority_queue<int, vector<int>, greater<int>> heap; // 小根堆
// greater<int> 是比较规则,表示较小的优先级更高
for (int x : a) {
heap.push(x);
if (heap.size() > k) {
heap.pop();
}
}
return heap.top();
}各种内排序的比较
| 排序方法 | 平均情况 | 最坏情况 | 最好情况 | 空间复杂度 | 稳定性 |
|---|---|---|---|---|---|
| 直接插入排序 | O($n^2$) | O($n^2$) | O($n$) | O(1) | 稳定 |
| 折半插入排序 | O($n^2$) | O($n^2$) | O($n \log_{2}{n}$) | O(1) | 稳定 |
| 希尔排序 | O($n^{1.3}$) | O(1) | 不稳定 | ||
| 冒泡排序 | O($n^2$) | O($n^2$) | O($n$) | O(1) | 稳定 |
| 快速排序 | O($n \log_{2}{n}$) | O($n^2$) | O($n \log_{2}{n}$) | O($\log_{2}{n}$) | 不稳定 |
| 简单选择排序 | O($n^2$) | O($n^2$) | O($n^2$) | O(1) | 不稳定 |
| 堆排序 | O($n \log_{2}{n}$) | O($n \log_{2}{n}$) | O($n \log_{2}{n}$) | O(1) | 不稳定 |
| 二路归并排序 | O($n \log_{2}{n}$) | O($n \log_{2}{n}$) | O($n \log_{2}{n}$) | O($n$) | 稳定 |
| 基数排序 | O($d(n+r)$) | O($d(n+r)$) | O($d(n+r)$) | O($r$) | 稳定 |
按平均时间复杂度分类
- 平方阶O($n^2$):简单排序方法,如直接插入、简单选择、冒泡排序
- 线性对数阶O($n \log_{2}{n}$):快速排序、堆排序、归并排序
- 线性阶O($n$):基数排序
按空间复杂度分类
- O($n$):归并排序,基数排序为O($r$)
- O($\log_{2}{n}$):快速排序
- O(1):其他排序方法
按稳定性分类
- 不稳定的:希尔排序、快速排序、堆排序、简单选择排序
- 稳定的:其他排序方法
直接插入排序
核心思想:
将已经排好的部分看作有序区,每次从无序区取一个元素,插入到合适的位置。
特点:
- 稳定排序
- 空间复杂度 O(1),原地排序
- 平均、最坏时间复杂度 O($n^2$),最好 O($n$)
- 适合数据量较小,或者原序列基本有序
折半插入排序
核心思想:
依旧是插入排序,只是在有序区内查找插入位置时用折半查找。
特点:
- 稳定排序
- 空间复杂度 O(1),原地排序
- 平均、最坏时间复杂度 O($n^2$),最好 O($n \log_{2}{n}$)
- 元素移动次数没有减少,优化的是“找位置”而非“挪元素”
希尔排序
核心思想:
又称缩小增量排序。先按较大间隔分组,对每组做插入排序;再逐渐缩小间隔,最后间隔为 1 时再做一次插入排序。
特点:
- 不稳定排序
- 空间复杂度 O(1),原地排序
- 时间复杂度不容易分析,O($n^{1.3}$)
冒泡排序
核心思想:
相邻元素两两比较,逆序则交换。每一趟会把当前最大值“冒泡”到末尾。
特点:
- 稳定排序
- 空间复杂度 O(1),原地排序
- 平均、最坏时间复杂度 O($n^2$),最好 O($n$)
快速排序
核心思想:
选一个枢轴 pivot,一趟划分,小的放左边,大的放右边,递归排序左右两边。
特点:
- 不稳定排序
- 空间复杂度 O($\log_{2}{n}$)
- 平均、最好时间复杂度 O($n \log_{2}{n}$),最坏 O($n^2$)
简单选择排序
核心思想:
每一趟从无序区中选出最小元素,放到无序区最前面。
特点:
- 不稳定排序
- 空间复杂度 O(1),原地排序
- 时间复杂度 O($n^2$)
堆排序
核心思想:
利用堆这种数据结构。升序排序则建立大根堆,每次取出堆顶最大元素放到末尾,再调整堆,重复。
特点:
- 不稳定排序
- 空间复杂度 O(1),原地排序
- 时间复杂度 O($n \log_{2}{n}$)
二路归并排序
核心思想:
把序列不断二分,分别排序后再把两个有序序列合并为一个有序序列。
特点:
- 稳定排序
- 空间复杂度 O($n$),需要额外辅助空间
- 时间复杂度 O($n \log_{2}{n}$)
基数排序
核心思想:
按照关键字的每一位进行分配和收集。通常是 LSD (最低位优先),越重要的位越在后面排序。
特点:
- 稳定排序
- 非比较排序
- 空间复杂度 O($r$)
- 时间复杂度 O($d(n+r)$)
- 需要大量元素移动,数据和队列均采用链表存储为好
9. 什么是 DFS?什么是 BFS?如何选择?
DFS 是深度优先遍历,思想是一条路径尽量向深处访问,走不通再回溯。它常用递归或栈实现,适合连通性判断、路径枚举、回溯搜索、拓扑排序等。
BFS 是广度优先遍历,思想是从起点按层次向外扩展。它常用队列实现,适合无权图最短路径、最少步数问题、树的层次遍历等。
选择原则:需要找所有方案、搜索路径、判断连通块时常用 DFS;需要按层扩展或求无权最短路时优先用 BFS。
10. 完全二叉树的结点个数、叶子数和高度有什么关系?如何编号?
完全二叉树按层从左到右连续编号。若根编号为 1,则结点 i 的左孩子为 2i,右孩子为 2i + 1,双亲为 floor(i / 2)。
含 n 个结点的完全二叉树高度为:
h = floor(log2 n) + 1 = ceil(log2(n + 1))
叶子结点数为:
ceil(n / 2)
若 2i > n,结点 i 无左孩子;若 2i + 1 > n,结点 i 无右孩子。
11. 如何在变化的数据结构上找到满足定值条件的实例?
这类问题通常用 DFS 或回溯。核心是维护“当前状态”,递归进入下一层时修改状态,返回时恢复状态。
在二叉树中找路径长度或路径和等于定值的路径,可从根或任意结点出发 DFS,维护当前路径和与路径数组。到达目标条件时输出路径,递归结束后撤销当前结点。
在整数集合中找元素之和等于定值的子集,可对每个元素做二选一:选或不选。递归参数通常包括当前下标 i、当前和 sum、当前选择集合。若 sum == target 输出;若 i == n 结束。若所有数非负,sum > target 时可以剪枝。
关键点是:状态要随递归变化,返回上一层时必须恢复,否则会影响其他分支。
模板如下:
void dfs(参数) {
if (结束条件) {
记录答案;
return;
}
for (选择 : 当前层可选范围) {
if (不合法) continue;
做选择;
dfs(下一层参数);
撤销选择;
}
}12. 什么是 B-树?怎样构造?什么是 B+树?二者差别是什么?
B-树是一种多路平衡查找树。m 阶 B-树中,每个结点最多有 m 棵子树、m - 1 个关键字;除根外的非叶结点至少有 ceil(m / 2) 棵子树;所有叶子结点处于同一层。
B-树插入时先找到应插入的叶结点,插入后若关键字数不超过上限则结束;若溢出,则按中间关键字分裂,中间关键字上移。分裂可能向父结点递归,根结点溢出会产生新根。
如
[20, 40]
/ | \
[10] [30] [50, 60]插入 70 后,右孩子变成 [50, 60, 70],此时溢出,把 60 上升到父结点得到 [20, 40, 60],父结点也溢出,中间关键字 40 继续上升,成为新的根,得到:
[40]
/ \
[20] [60]
/ \ / \
[10] [30] [50] [70]B+树是 B-树的变形,通常所有数据记录都存放在叶子结点,非叶结点只起索引作用,用来决定查找方向,叶子结点中才是真正的数据关键字,叶子结点之间按关键字顺序链接。
二者差别:B-树查找可能在非叶结点结束;B+树查找必须到叶子。B+树叶子链表便于顺序查找和范围查询,因此数据库索引中更常用。
13. 什么是哈夫曼编码?如何生成?如何计算压缩比?
哈夫曼编码是根据字符出现频度构造哈夫曼树得到的最优前缀编码,频度高的字符编码短,频度低的字符编码长。任一字符编码都不是另一个字符编码的前缀。
生成方法:把每个字符及其频度看作一棵单结点树;每次选权值最小的两棵树合并成新树,新树权值为两者之和;重复直到只剩一棵树。规定左分支为 0、右分支为 1,或反过来但保持统一,从根到叶子的路径就是该字符编码。
带权路径长度:
WPL = sum(字符频度 * 编码长度)
压缩后总位数等于 sum(字符频度 * 哈夫曼编码长度)。压缩比通常用 压缩后位数 / 原编码位数,或用节省比例 1 - 压缩后位数 / 原编码位数,要看题目要求。
举例:
| 字符 | 频率 | 编码 | 编码长度 |
|---|---|---|---|
| A | 5 | 1100 | 4 |
| B | 9 | 1101 | 4 |
| C | 12 | 100 | 3 |
| D | 13 | 101 | 3 |
| E | 16 | 111 | 3 |
| F | 45 | 0 | 1 |
每次选择最小的两个合并,
A5 + B9 -> 14
C12 + D13 -> 25
14 + E16 -> 30
25 + 30 -> 55
F45 + 55 -> 100最终得到哈夫曼树,写出相应哈夫曼编码:
(100)
/ \
F45 (55)
0 / \
(25) (30)
/ \ / \
C12 D13 (14) E16
0 1 / \ 1
A5 B9
0 1带权路径长度 WPL = $\sum {(字符频度 \times 编码长度)}$
= 5×4 + 9×4 + 12×3 + 13×3 + 16×3 + 45×1
= 20 + 36 + 36 + 39 + 48 + 45
= 224 bit压缩比 = 压缩后大小 / 压缩前大小
原本使用定长编码,字符有 6 种,每个至少需要 ceil(log2 6) = 3 bit
压缩前总位数为 100 × 3 = 300 bit
压缩比 = 224 / 300 ≈ 74.67%14. 什么是图的邻接表、逆邻接表、十字链表、邻接多重表?
邻接表是图的一种链式存储结构。对每个顶点建立一个单链表,存放从该顶点出发的所有邻接点。无向图中每条边会在两个顶点链表中出现;有向图中通常存出边。
逆邻接表用于有向图,记录一个结点的前驱结点有哪些。对每个顶点建立链表,存放所有指向该顶点的入边,便于求入度和查找前驱。
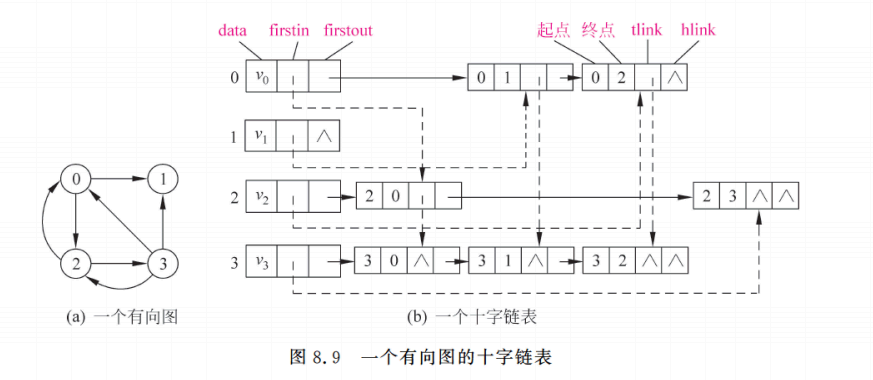
十字链表用于有向图,每条弧结点同时挂在弧尾顶点的出边链表和弧头顶点的入边链表中,因此能同时方便查找入边和出边。
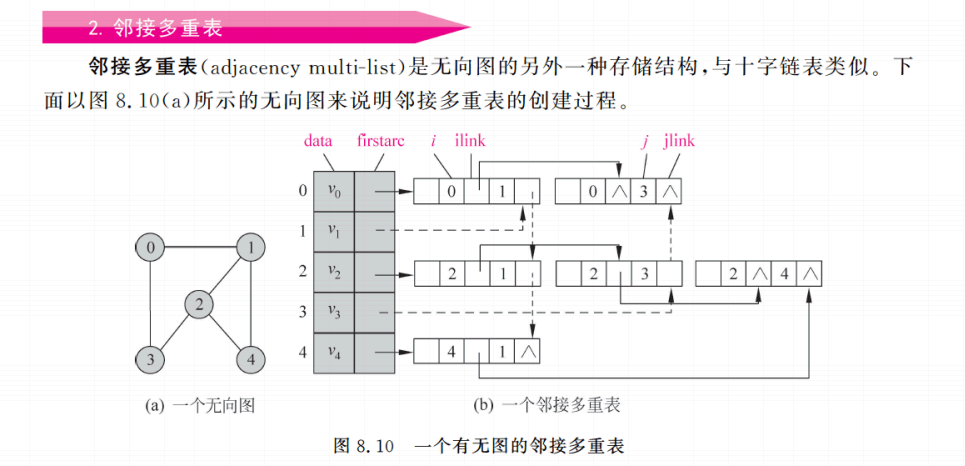
邻接多重表用于无向图,每条边只存储一个边结点,但该边结点同时连接到两个顶点的边链表中,避免邻接表中无向边重复存储。
15. 什么是循环队列?rear 和 front 通常代表什么?满和空条件有什么关系?
循环队列是把顺序队列的存储空间看成首尾相接的环,用取模运算实现队尾和队头的循环移动。
常见约定中,front 指向队头位置或队头前一位置,rear 指向队尾元素后一位置。具体含义要以教材定义为准,但判空判满必须与定义配套。
若采用牺牲一个存储单元的方法:
- 队空:
front == rear。 - 队满:
(rear + 1) % MaxSize == front。 - 队长:
(rear - front + MaxSize) % MaxSize。
空和满不能使用同一个条件。若不牺牲空间,就必须增加计数器 count 或标志位 tag 区分。
16. 什么是分块查找?如何进行?效率如何计算?
分块查找又称索引顺序查找。它把表分成若干块,块间有序,块内可以无序,并为每块建立索引项,索引项通常包含该块最大关键字和块起始位置。
查找时先在索引表中确定目标可能所在的块,再在该块内部顺序查找。
平均查找长度:
ASL = 查索引表的平均比较次数 + 块内查找的平均比较次数
若有 n 个元素,分成 b 块,每块 s 个元素,索引和块内都顺序查找,则近似如下计算(等差数列求和):
ASL = (b + 1) / 2 + (s + 1) / 2
17. 什么是树的层次遍历?使用什么辅助结构?
树的层次遍历是按从上到下、从左到右的顺序访问结点。
辅助数据结构是队列。先把根结点入队,然后反复出队访问一个结点,并把它的孩子按从左到右的顺序入队。队列为空时遍历结束。
18. 什么是二路归并排序?复杂度和特点是什么?
二路归并排序是把两个相邻的有序子表合并成一个有序表,并不断扩大有序段长度,直到整个序列有序。
每趟归并处理所有元素,时间为 O(n);共需 ceil(log2 n) 趟,因此总时间复杂度为 O(n log n)。它需要辅助数组,空间复杂度为 O(n)。二路归并排序是稳定排序,且时间复杂度与初始序列状态关系不大。
19. 什么是图的单源最短路径问题?常见方法有哪些?
单源最短路径是指给定一个源点,求该源点到图中其余各顶点的最短路径。
常见方法:
- 无权图或等权图:用 BFS,复杂度
O(n + e)。 - 权值非负:用 Dijkstra 算法,邻接矩阵实现通常为
O(n^2)。 - 存在负权边但无负权回路:可用 Bellman-Ford 算法,复杂度
O(ne)。
Dijkstra 的基本思想是每次从未确定顶点中选当前距离最小者加入确定集合,再用它更新邻接点距离。
20. 什么是快速排序?不同条件下复杂度如何?
快速排序是一种交换排序。它通过一次划分选定一个枢轴元素,使枢轴左侧元素不大于它、右侧元素不小于它,于是枢轴到达最终位置,再递归排序左右子序列。
复杂度:
- 平均情况:
O(n log n)。 - 最好情况:每次划分比较均衡,
O(n log n)。 - 最坏情况:每次划分极不均衡,如已有序且枢轴选端点,
O(n^2)。 - 空间复杂度:平均递归栈
O(log n),最坏O(n)。
快速排序不稳定。
21. 满足特定条件时,二叉树形状数由什么决定?为什么要注意度为 1 的结点?
若只给出先序和后序遍历序列,二叉树通常不能唯一确定。原因是度为 1 的结点只有一个孩子,这个孩子可以是左孩子,也可以是右孩子,而先序和后序序列无法区分这两种情况。
因此,在这类条件下,二叉树可能的形状数主要由度为 1 的结点个数决定。若有 k 个度为 1 的结点,通常有 2^k 种左右孩子安排方式。
如果二叉树是满二叉树,或已知中序遍历,则形状可能唯一。
22. 什么是多关键字排序?什么是基数排序?复杂度如何?
多关键字排序是记录有多个排序关键字时,按关键字优先级进行排序。例如先按 k1,k1 相同再按 k2。使用稳定排序时,应先排次关键字,再排主关键字,即越重要的关键字越后排序。
基数排序是一种多关键字排序方法,把关键字拆成若干位,按每一位进行分配和收集。它不需要关键字之间的整体比较。最低位优先 LSD 从低位到高位处理;最高位优先 MSD 从高位到低位处理。
复杂度为:
O(d(n + r))
其中 d 是关键字位数,r 是基数,空间复杂度通常为 O(r)。
23. 什么是 KMP 算法?目标串、模式串、next 数组是什么?
KMP 是一种改进的串模式匹配算法,用于在目标串中查找模式串。目标串是被查找的主串,模式串是要匹配的子串。
普通匹配失败时可能回退目标串指针;KMP 利用模式串自身的前后缀信息,使目标串指针不回退,只移动模式串。
next 数组表示模式串在某位置失配时,模式串应回退到的位置,本质上记录当前位置之前子串的最长相等真前缀和真后缀信息。
KMP 时间复杂度为 O(n + m),其中求 next 需要 O($m$),匹配需要 O($n$)。
主串指针 i 不回退,利用 next 数组避免重复比较。失配时,i 不变,j = next[j]。
24. 常用排序算法有哪些?稳定性、复杂度如何?单趟能决定最终位置的有哪些?
常用排序算法包括直接插入、折半插入、希尔、冒泡、快速、简单选择、堆、二路归并、基数排序。
稳定排序:直接插入排序、折半插入排序、冒泡排序、二路归并排序、基数排序。
不稳定排序:希尔排序、快速排序、简单选择排序、堆排序。
平均时间复杂度为 O(n^2) 的有直接插入、折半插入、冒泡、简单选择。平均为 O(n log n) 的有快速、堆、归并。基数排序为 O(d(n + r))。
单趟能确定某些元素最终位置的排序包括:冒泡排序、快速排序、简单选择排序、堆排序。归并排序每趟形成局部有序段,但通常不能说单个元素最终位置均已确定;插入排序形成局部有序区,但其中元素最终位置也可能继续变化。
25. 什么是对半搜索算法?适用条件、复杂度、二叉判定树和 ASL 如何理解?
对半搜索也称折半查找或二分查找。它每次取有序表中间元素与目标比较,若相等则成功;若目标较小,则在左半区继续;若目标较大,则在右半区继续。
适用条件:
- 查找表必须按关键字有序。
- 必须支持随机存取,因此通常要求顺序存储。
时间复杂度为 O(log2 n)。
二叉判定树描述折半查找的比较过程。根结点是第一次比较的中间元素,左子树表示在左半区继续查找,右子树表示在右半区继续查找。成功 ASL 可按各结点所在层数求平均;若各元素查找概率相等,则 ASL = 各结点比较次数之和 / n。
26. 什么是递归?数组递归如何判断结束?如何挑选不同元素进行组合?
递归是函数直接或间接调用自身,把大问题分解为规模更小的同类问题。递归必须有递归出口和递归体,否则会无限调用。
数组递归通常用下标作为参数。常见结束条件包括:i == n 表示已经处理完所有元素;low > high 表示区间为空;low == high 表示区间只剩一个元素;组合问题中还可用“已选数量达到要求”或“当前和达到目标”作为结束条件。
挑选不同元素进行组合时,常用回溯法。对每个元素有两种选择:选或不选。递归进入下一层前记录选择,返回时撤销选择。这样可以枚举所有组合。
path.push_back(nums[i]); // 选择当前元素
dfs(nums, i + 1, path); // 进行递归
path.pop_back(); // 递归回来后撤销选择27. 什么是堆?堆有什么性质?如何构建堆?
堆是一棵按数组顺序存储的完全二叉树,并满足堆序性质。大根堆中任一结点关键字都不小于其孩子;小根堆中任一结点关键字都不大于其孩子。
堆的性质:
- 逻辑结构是完全二叉树。
- 物理结构通常是数组。
- 若根编号为 1,结点
i的孩子为2i和2i + 1。 - 大根堆堆顶是最大元素,小根堆堆顶是最小元素。
构建堆通常从最后一个非叶结点 floor(n / 2) 开始,依次向前对每个结点执行向下调整,直到根结点。建堆时间复杂度为 O(n)。堆排序递增排序通常建大根堆,每次把堆顶最大元素与当前堆尾交换,再缩小堆并调整。

